I’m not an expert, but it has something to do with full words vs partial words. It also can’t play wordle because it doesn’t have a proper concept of individual letters in that way, its trained to only handle full words
they don’t even handle full words, it’s just arbitrary groups of characters (including space and other stuff like apostrophe afaik) that is represented to the software as indexes on a list, it literally has no clue what language even is, it’s a glorified calculator that happens to work on words.
not really, a basic calculator doesn’t tend to have variables and stuff like that
i say it’s a glorified calculator because it’s just getting input in the form of numbers (again, it has no clue what a language or word is) and spitting back out some numbers that are then reconstructed into words, which is precisely how we use calculators.
LLMs have three major components: a massive database of “relatedness” (how closely related the meaning of tokens are), a transformer (figuring out which of the previous words have the most contextual meaning), and statistical modeling (the likelihood of the next word, like what your cell phone does.)
LLMs don’t have any capability to understand spelling, unless it’s something it’s been specifically trained on, like “color” vs “colour” which is discussed in many training texts.
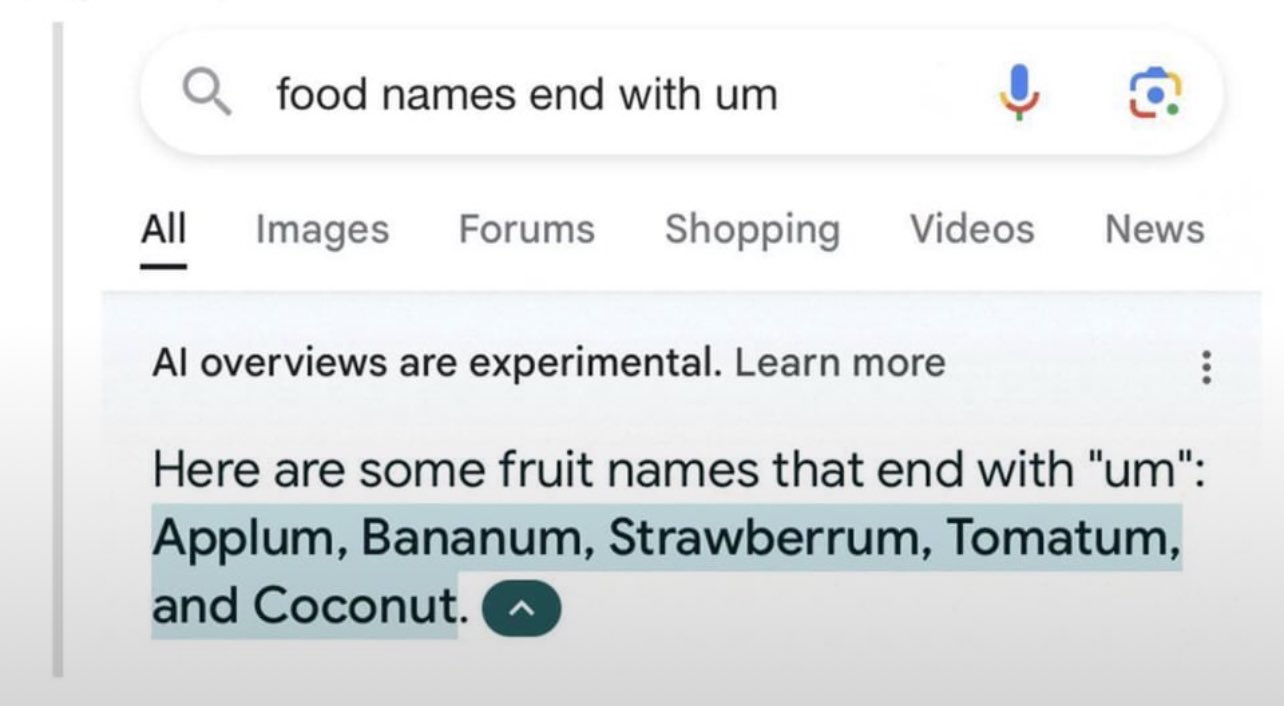
"Fruits ending in ‘um’ " or "Australian towns beginning with ‘T’ " aren’t talked about in the training data enough to build a strong enough relatedness database for, so it’s incapable of answering those sorts of questions.
It can’t see what tokens it puts out, you would need additional passes on the output for it to get it right. It’s computationally expensive, so I’m pretty sure that didn’t happen here.

{kind=link}
It’s crazy how bad d AI gets of you make it list names ending with a certain pattern. I wonder why that is.
I’m not an expert, but it has something to do with full words vs partial words. It also can’t play wordle because it doesn’t have a proper concept of individual letters in that way, its trained to only handle full words
they don’t even handle full words, it’s just arbitrary groups of characters (including space and other stuff like apostrophe afaik) that is represented to the software as indexes on a list, it literally has no clue what language even is, it’s a glorified calculator that happens to work on words.
I mean, isn’t any program essentially a glorified calculator?
not really, a basic calculator doesn’t tend to have variables and stuff like that
i say it’s a glorified calculator because it’s just getting input in the form of numbers (again, it has no clue what a language or word is) and spitting back out some numbers that are then reconstructed into words, which is precisely how we use calculators.
That’s interesting, didn’t know
LLMs aren’t really capable of understanding spelling. They’re token prediction machines.
LLMs have three major components: a massive database of “relatedness” (how closely related the meaning of tokens are), a transformer (figuring out which of the previous words have the most contextual meaning), and statistical modeling (the likelihood of the next word, like what your cell phone does.)
LLMs don’t have any capability to understand spelling, unless it’s something it’s been specifically trained on, like “color” vs “colour” which is discussed in many training texts.
"Fruits ending in ‘um’ " or "Australian towns beginning with ‘T’ " aren’t talked about in the training data enough to build a strong enough relatedness database for, so it’s incapable of answering those sorts of questions.
It can’t see what tokens it puts out, you would need additional passes on the output for it to get it right. It’s computationally expensive, so I’m pretty sure that didn’t happen here.
With the amount of processing it takes to generate the output, a simple pass over the to-be final output would make sense…
doesn’t it work literally by passing in everything it said to determine what the next word is?
it chunks text up into tokens, so it isn’t processing the words as if they were composed from letters.