

This was a terrible article from a serial plagiarist who refuses to do work or cite sources.
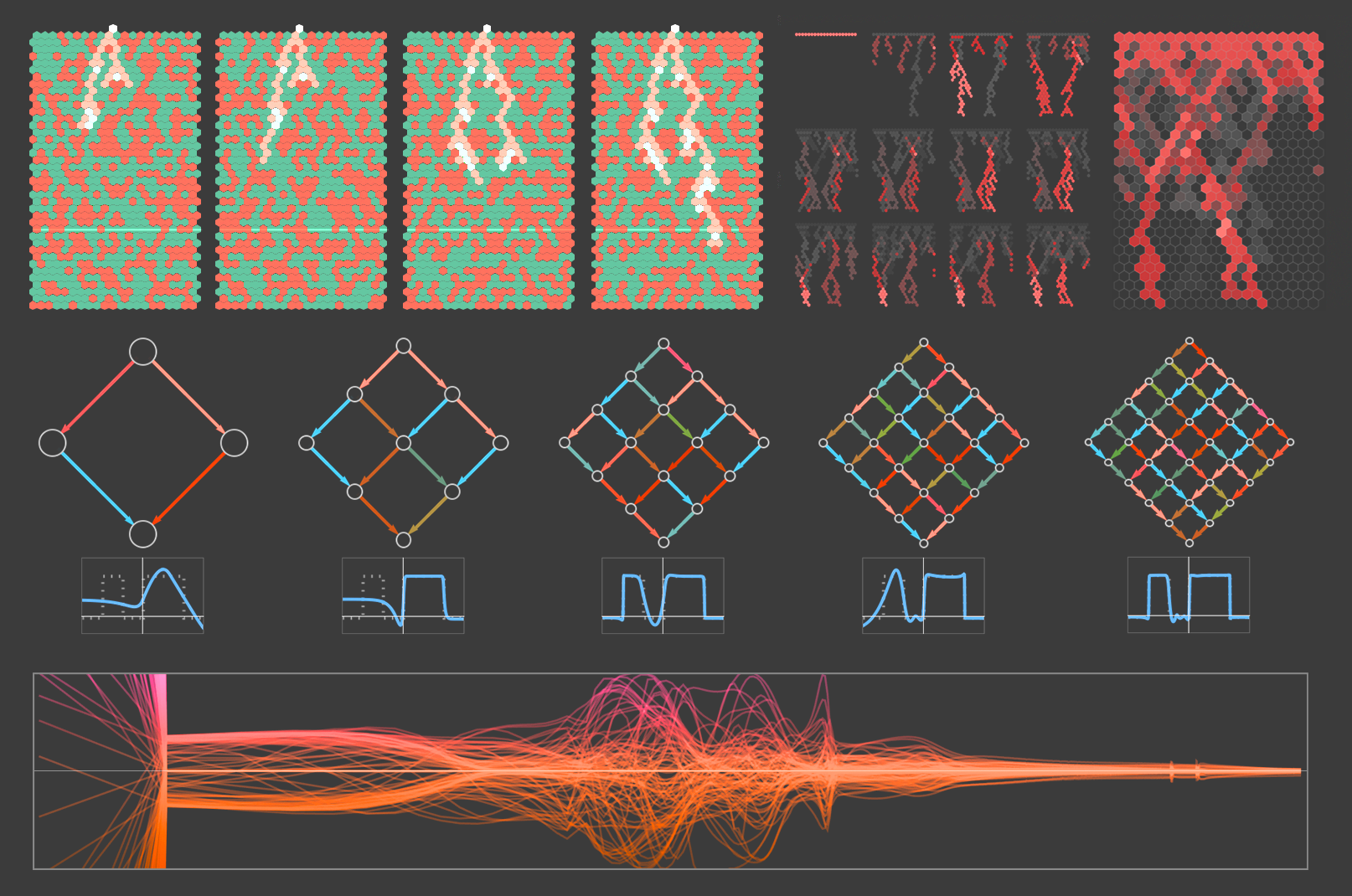
But at a fundamental level we still don’t really know why neural nets “work”—and we don’t have any kind of “scientific big picture” of what’s going on inside them.
Neural networks are Turing-complete just like any other spreadsheet-style formalism which evolves in time with loops. We’ve had several theories; the best framework is still PAC learning, which generalizes beyond neural networks.
And in a sense, therefore, the possibility of machine learning is ultimately yet another consequence of the phenomenon of computational irreducibility.
This is masturbatory; he just wants credit for Valiant’s work and is willing to use his bullshit claims about computation as a springboard.
Instead, the story will be much closer to the fundamentally computational “new kind of science” that I’ve explored for so long, and that has brought us our Physics Project and the ruliad.
The NKoS programme is dead in the water because — as has been known since the late 1960s — no discrete cellular automaton can possibly model quantum mechanics. Multiple experts in the field, including Aaronson in quantum computing and Shalizi in machine learning, have pointed out the utter futility of this line of research.
deleted by creator
I don’t know a lot about AI or machine learning so I’d take what I say with a grain of salt. I do know a lot about computers, though. I’m just spit balling here.
This is kinda the reason why I think this “AI” hype is a joke. I get the idea behind it, but a computer is only as smart as the user. Or in this case the data that it soaks up. And as advanced as they are they are mostly still just a novelty save for very specific purposes. The whole idea of a black box in machine learning is just inefficient and wasteful. The fact that we have no idea how these AI’s achieve their output is a big problem and a huge waste of resources. In a basic sense, if you put 2+2 into a calculator it will give an output of 2. If you put 2+2-(3x9-18)+7 into a calculator it will give you an output of 2. If all you see is the result you will have no idea how much processing power is being wasted on unnecessary processes. As long as we keep shoving information into these things without thinking about what we put into them they will only get more wasteful with unnecessary data. I know they add certain parameters and weights to negate things like this. But there’s no way in hell they’ve accounted for even 1% of what would be needed.
Don’t get me wrong, I understand the practicality of using machine learning. I just think the way we are building it from the ground up is too simple for what we are trying to achieve at this point. I honestly think we are reaching a plateau with this kind of machine learning. We need more parameterization if we want it to get better.
I don’t know a lot about AI or machine learning so I’d take what I say with a grain of salt.
Yeah…
I mean I literally warned you before you read it. Maybe instead of being passive aggressive you could help educate or correct people on the topic instead of treating them like they’re an idiot. I’m more than open to criticism about this topic and I’m just learning as I go.
Yeah fair enough. That was a bit mean, sorry.
I think the main issue is that ML isn’t useless just because we don’t understand how it works. It clearly does work and we can use that. It’s hardly unique in that way either. There are a gazillion medicines that work but we don’t really know how. We’re not going to abandon them just because we don’t understand them.
And it’s not like people aren’t trying to understand how they work; it’s just really difficult.
The calculator analogy also makes no sense. You can’t build a working speech recognition engine by manually entering equations for phonemes or whatever. That’s actually not a million miles away from how speech recognition worked in the 90s and 2000s… or I should say “didn’t work”.
Dude, we all saw your anti-woke meltdown. Nobody is taking what you say seriously.
your anti-woke meltdown
You mean these totally reasonable comments that almost everyone upvoted? lol ok.
Nobody is taking what you say seriously.
Ah yeah that must be why everyone except you upvoted my comment… Come on dude. This isn’t even on topic.
Feel free to say anything on-topic. Right now you’re in Reddit mode: nothing to contribute, but really eager to put words into the box. This is a Wolfram article; you could be on-topic with as little as “lol wolfram sux”.
Err… Why are you criticising me for going off-topic when it was literally you that did it? Weird.
Good points and all, but 2 + 2 != 2…
Unless it is an ai calculator
Lol I’m not gonna change it.
I was gonna say, op needs a new calculator.
Didn’t even notice. I’m not gonna change it. :)
More data doesn’t mean more processing.
They have a fixed number of interconnected nodes that encode the data via the weights between them.
So processing requirements are the same. Training is where a lot of power goes though.
This also gives it the ability to solve things we don’t have an equation for. As long as we know the input and output we can train an NN to do the calculations even if we don’t know the equation ourselves.
The black box nature is a problem but that’s also where it’s power comes from.
I see what you mean. I made a comment further down as a response to someone else where I go into more detail about my train of thought where I explain more of the issues I’ve found with this type of machine learning.
I think that the mistake is thinking that “smart” is a meaningful word. I’d encourage you to learn about the technology you’re critiquing and not listen to memetic bullshit from articles like the one we’re discussing. Consider:
- AI/cybernetics/robotics (same field, different perspectives) is always only useful for specific tasks, never for general replacement of humans
- Black-box treatments of machine learning are only done at the most introductory level and there are several ways to examine how e.g. a Transformers-based language model’s weights contribute to its outputs
- We have many useful theories about how to learn functions in general, with machine learning as a special case
This has happened before and it will happen again. I’m sure you’ve seen the phrase “AI winter” floating around.
I encourage you to read the comment I left down lower in response to someone else. I go into more details about the point I’m trying to make. As I mentioned above I’m not an expert on the topic. But I am open to criticism. It’s kinda the reason I make comments like this in the first place. I’m not trying to rile people up but get a discussion going.
I appreciate your feedback. I’m learning as I go
What do you think about what Steven Wolfram wrote here?
I’ve only made it about half way through as of right now. Like I stated previously, I’m not an expert. But I still believe in my statement above. From what I can gather it takes extreme amounts of effort to even figure out how a neural network arrived at the conclusion it came up with. And that still seems like a backwards way of approaching it. You’re starting at the end and working your way backwards. It’s not a bad method. Just in my opinion I believe it’s the wrong method.
If you compare this to something like a scientific theory it doesn’t quite match up to the procedure. Things like gravity exist regardless of the formulas used to determine it. Because of this we were able to figure out the formulas required to calculate it. With neural network’s we already know how they do what they do because we are the ones that programmed them, at least initially. I find it more analogous to solving for the velocity of an object falling over and over again. You already know the formula, so it’s relatively easy. You just work your way backwards from the result. Sure we can add things like drag, friction, and terminal velocity to add more parameterization and make it more accurate. But even with something like this, the increase in accuracy slowly decreases while the processing power increases.
Basically what I’m trying to say is that I believe the “formula” is not quite correct. It’s adjacent to what we are looking for. You can keep making the initial conditions as complicated as you want but eventually you will reach the realistic computational limitations of said conditions. If the initial conditions are not quite correct, you can only get it within a certain degree of accuracy before it starts to either diverge or plateau.
I’m not saying neural network’s are wrong. I’m saying that we are making the wrong kinds of neural network’s. Instead of forcing massive amounts of data into these things until we get the result we want, we should try and find more ideal initial conditions that are more equipped to solve the problems we are trying to solve. As I mentioned above the result doesn’t matter when the method of solving has unnecessary, or even incorrect, steps involved in the processes.
I am a layman when it comes to neural networks and machine learning, as I stated above. But this is what I see whenever I hear about this kinda stuff. It just all seems so wasteful because we are so focused on the results. It feels like a confirmation bias when we see the results we were expecting so we ignore the underlying issues. If the “black box” is causing issues it seems entirely more likely that it was set up for failure. If you were calculating a theoretical pendulum and it starts doing 360 no scopes instead of going back and forth then the laws and conditions assigned to it were incorrect.
Edit: Added some stuff in case I explained my train if thought poorly.
Interesting, it reminds me of Ptolemy adding more and more epicycles to explain observations, instead of considering that his model was wrong.
https://en.m.wikipedia.org/wiki/Deferent_and_epicycle#The_number_of_epicycles
I don’t think that this critique is focused enough to be actionable. It doesn’t take much effort to explain why a neural network made a decision, but the effort scales with the size of the network, and LLMs are quite large, so the amount of effort is high. See recent posts by (in increasing disreputability of sponsoring institution) folks at MIT and University of Cambridge, Cynch.ai, Apart Research, and University of Cambridge, and LessWrong. (Yep, even the LW cultists have figured out neural-net haruspicy!)
I was hoping that your complaint would be more like Evan Miller’s Transformers note, which lays out a clear issue in the Transformers arithmetic and gives a possible solution. If this seems like it’s over your head right now, then I’d encourage you to take it slowly and carefully study the maths.
Fair enough. I’m still at work so I’ve only skimmed these so far. I appreciate the feedback and links and I’ll definitely look into it more.
I completely agree that my critique isn’t focused enough. I slapped that comment together entirely too fast without much deeper thought involved. I have a very surface level understanding of this kinda stuff. Regardless, I do like sharing my opinion from an outsiders perspective. Mostly because I enjoy the discussion. It’s always an opportunity to learn something new, even if it ruffles a few feathers along the way. I know that whenever I’m super invested in a topic, no matter what it is, I sometimes get so soaked up in it all that I tend to ignore outside influences.
