

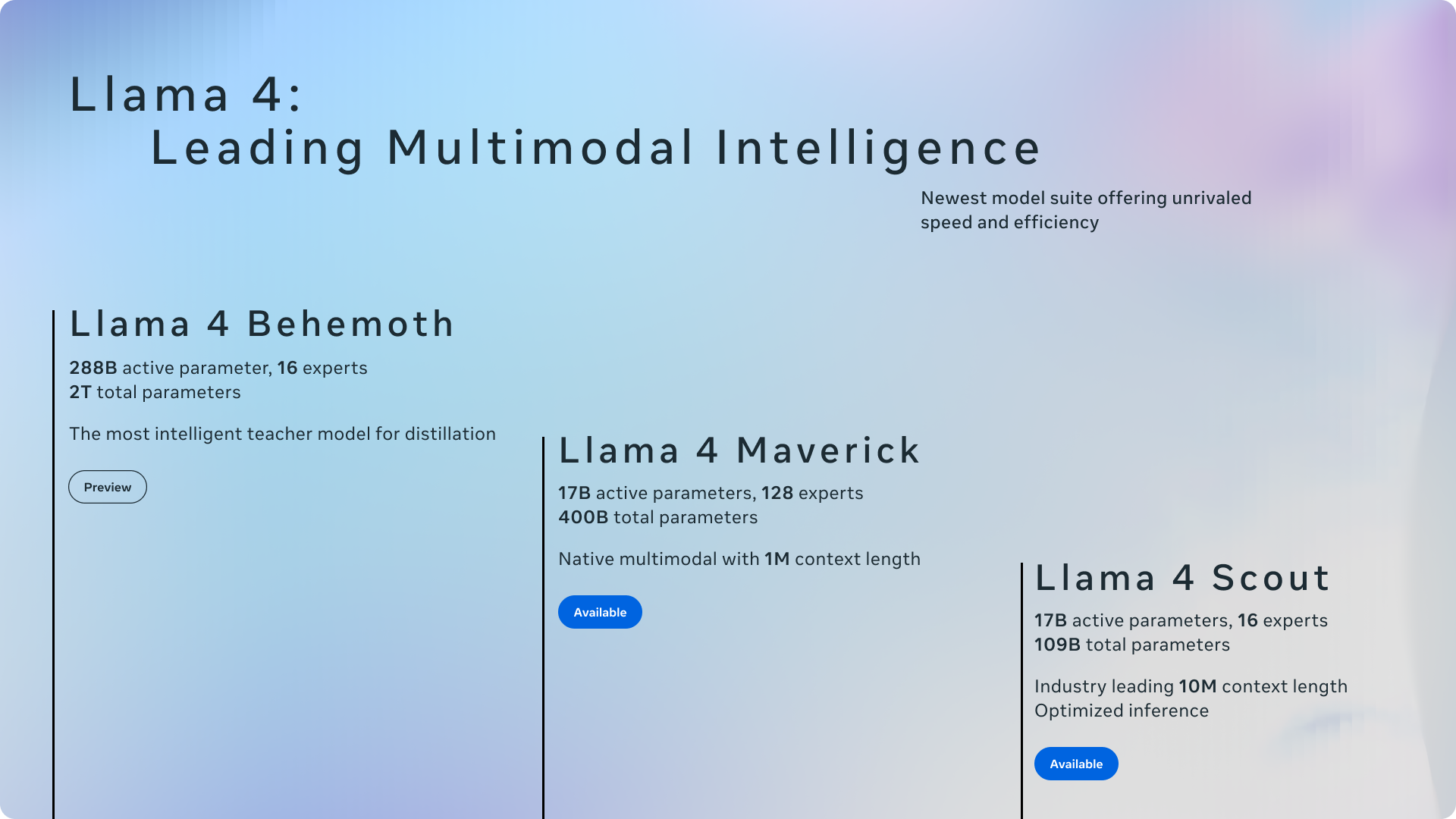
- We’re sharing the first models in the Llama 4 herd, which will enable people to build more personalized multimodal experiences.
- Llama 4 Scout, a 17 billion active parameter model with 16 experts, is the best multimodal model in the world in its class and is more powerful than all previous generation Llama models, while fitting in a single H100 GPU. Additionally, Llama 4 Scout offers an industry-leading context window of 10M and delivers better results than Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across a broad range of widely reported benchmarks.
- Llama 4 Maverick, a 17 billion active parameter model with 128 experts, is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding—at less than half the active parameters. Llama 4 Maverick offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena.
- These models are our best yet thanks to distillation from Llama 4 Behemoth, a 288 billion active parameter model with 16 experts that is our most powerful yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
- Download the Llama 4 Scout and Llama 4 Maverick models today on llama.com and Hugging Face. Try Meta AI built with Llama 4 in WhatsApp, Messenger, Instagram Direct, and on the web.
Why are we only inventing ai nowadays? Where is my flying car?
When students progress in school, they are no longer interested in simple problems and need harder problems as challenges to stay motivated. They got something similar in their work :
quote :
To address this, we removed more than 50% of our data tagged as easy by using Llama models as a judge and did lightweight SFT on the remaining harder set. In the subsequent multimodal online RL stage, by carefully selecting harder prompts, we were able to achieve a step change in performance.
Eventually, we will ask a question to one of those systems and they will consider us with disdain.
Also, for what i read in their work, elaborating such systems becomes more and more convoluted. Eventually, people working on these things, will lose the trail of what they did before. So, they will forget why they came to do something one specific way.
Gonna put it on fridges and air conditioners or something?
Because it’s hot🔥?
I hear about AI Innovation and my eyes roll fast enough to break C.
